ASF.RL.12.16AZSF照明開關系統 燈控系統的創新與計算機軟硬件開發銷售

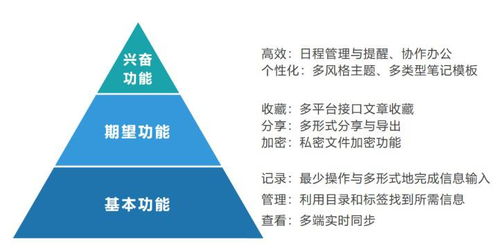
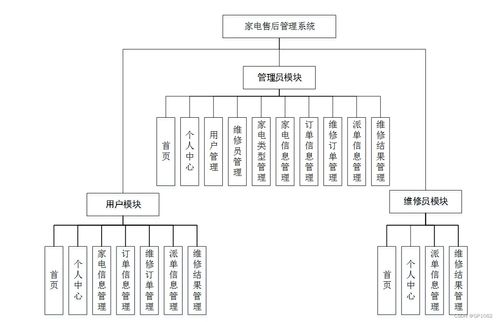
ASF.RL.12.16AZSF照明開關系統代表了現代燈控技術與計算機軟硬件開發深度融合的先進成果。該系統不僅是一個簡單的照明控制設備,更是一個集智能化、網絡化與高效能于一體的綜合解決方案,廣泛應用于商業建筑、智能家居、工業照明及公共設施等領域。
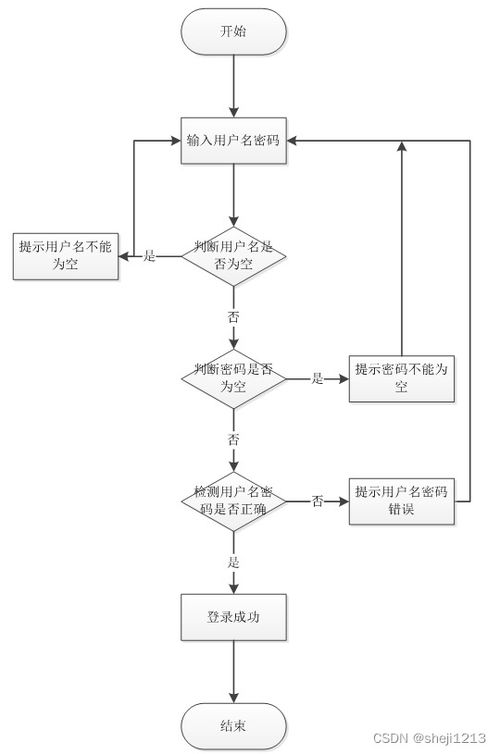
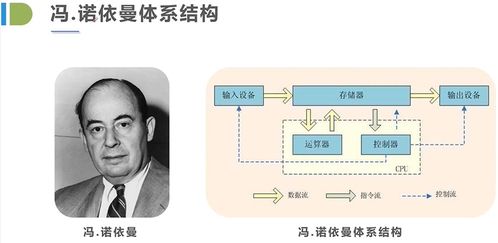
系統核心基于先進的計算機硬件平臺,采用高性能的微處理器和穩定的電路設計,確保控制的精確性與可靠性。軟件部分則通過定制化的開發,實現了用戶友好的操作界面、靈活的編程設置以及強大的遠程監控功能。用戶可以通過移動應用、網頁端或中央控制面板,輕松調整照明場景、設置定時開關、監控能耗狀態,并實現與其他智能系統的聯動。
在開發過程中,團隊注重軟硬件的協同優化。硬件上,采用模塊化設計便于安裝維護,并支持多種通信協議如Wi-Fi、Zigbee、藍牙等,確保兼容性與擴展性。軟件方面,通過持續迭代更新,增強系統的安全性、穩定性和功能性,例如加入人工智能算法以實現自適應調光、節能預測等智能特性。
銷售策略上,ASF.RL.12.16AZSF系統面向多元化市場,既提供標準化的產品包,也支持根據客戶需求進行定制開發。通過線上線下渠道結合,與建筑商、工程商及終端用戶建立緊密合作,同時提供全面的技術支持和售后服務,確保系統長期穩定運行。
總而言之,ASF.RL.12.16AZSF照明開關系統通過計算機軟硬件的創新開發與銷售,推動了燈控行業的智能化進程,為節能環保和用戶體驗提升貢獻了重要力量。
如若轉載,請注明出處:http://www.fsydcb.cn/product/56.html
更新時間:2026-05-28 15:45:37